

Outliers for data cleaning and model robustness
تمیز کردن دادهها و دادههای پرت
در این پست قصد داریم شما را با مفهوم دادههای پرت (Outliers)، نحوه شناسایی آنها در یک دیتاست و تاثیر مخرب آنها و حل این مشکل آشنا کنیم. چون شناسایی و حل مشکل دادههای پرت، یکی از مهمترین وظایف در تمیز کردن دیتا (Data Cleaning) ست. از طرفی، تمیز کردن دادهها به عنوان اولین قدم در پردازش دادهها حائز اهمیت است. چون ما برای بکارگیری مدلهای یادگیری ماشین برای مثال در پروژههای دیتاساینس به دادههای با کیفیت نیازمندیم.
بطور کلی دادههای پرت باید در دو شرط کلی زیر صدق کنند:
- outlier<Q1-1.5(IQR)
- outlier>Q3+1.5(IQR)
که در آن Q1 نشان دهنده چارک اول، Q3 نشاندهنده چارک سوم و IQR تفاضل چارک اول از چارک سوم میباشد.
در دوره آمار برای علم داده در به آوران سیستم گیل، تمام مفاهیم آماری لازم برای پروژههای دیتاساینس آموزش داده میشود.
اهمیت شناسایی دادههای پرت:
در شکل زیر به آسانی مشاهده میکنیم چطور دادههای پرت میتوانند ضریب همبستگی و نتیجه پیش بینی را خراب کنند. حتی اگر تعداد آنها در مقایسه با دادههای دیگر بسیار کم باشد. شکل زیر این موضوع را آشکار میکند.
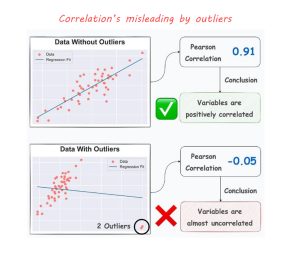
مشاهده میکنیم اضافه کردن تنها دو داده پرت نتیجه ضریب همبستگی و خط رگرسیون را کاملاً تغییر داد.
به عنوان یک راه حل، میتوان برای متغیرها دو به دو نمودار (scatter plot) رسم کرد و همبستگی و وضعیتشان را به صورت جداگانه مورد بررسی قرار داد.
از ابزارهای جالب برای مشاهده دادههای پرت، DropBox است. در دوره آموزشی پایتون به آن به طور مفصل خواهیم پرداخت.

پایداری در مدلهای یادگیری ماشین (Robustness in machine learning models)

در یادگیری ماشین، پایداری مُدل به توانایی مدل برای پایداری نگهداری و عملکرد منطقی آن علی رغم انحرافات، عدم قطعیتها و یا آشفتگی در داده ورودی میباشد.
اساساً یک مدل پایدار باید نسبت به داده جدید دیده شده، داده نویز، داده پرت یا حملات احتمالی قابل توسعه باشد. این باعث اطمینان ما میشود که مدل دقیق و قابل اعتماد باقی میماند. حتی در سناریوهای واقعی، جائیکه ممکن است در داده آموزش training data)) تغییر کند.
جنبههای کلیدی Robustness:
- قابلیت توسعه
یک مدل پایدار میتواند روی دادهای که آموزش ندیده باشد هم بطور دقیق پیش بینی را انجام دهد. این توانایی یادگیری آنرا در یادگیری الگوها نشان میدهد به جای بخاطر سپردن مجموعه آموزش.
- پایداری نسبت به نویز و داده پرت
مدلهای پایدار کمتر تحت تاثیر دادههای نویز هستند و میتوانند همچنان پیش بینیهای منطقی ایجاد کنند.
- پایداری شدید
این جنبه روی توانایی مدل برای مقابله با حملات عمدی که میتواند باعث خطا یا طبقه بندی اشتباه شود تکیه می کند که اغلب از طریق ورودی اتفاق میافتد.
- انتقال توزیع داده
توزیع دادهها میتواند تحت تاثیر زمان یا برحسب موضوعات مختلف تغییر کند. یک مدل پایدار میتواند با این انتقالها و عملکرد نگهداری خودش را تطبیق دهد.
چرا پایداری (Robustness) مهم هست؟
- قابلیت اطمینان
- جلوگیری از خطاها و طبقه بندی های اشتباه
- کاربردهای عمومی یک مدل پایدار میتواند در محیطهای گوناگون در زمینه های مختلف اجرا شود.
چطور پایداری مدل را بهبود دهیم؟
- کیفیت دادهها و افزایش دادهها
- جلوگیری از overfitting
- مدلهای ادغامی
- …
برای شرکت در دورههای حوزه دیتا مثل آموزش پروژه محور پایتون در رشت، یادگیری ماشین با پایتون، یادگیری عمیق با پایتون، مدلهای زبانی بزرگ LLMs و دریافت مشاوره تخصصی تحصیلی و شغلی میتوانید با به آوران سیستم گیل با شماره ۳۲۰۰۸۵۵۴-۰۱۳ تماس حاصل فرمائید.
برای آگاهی از تازههای حوزه دیتا و تکنولوژی به کانال اینستاگرام ما به نشانی ai.academy97 بپیوندید.